Building up a Research Repository
Why and how the UX Research Team approached setting up a research repository
Why a Research Repository?
When the immowelt research team started off, we still had to argue, that it is useful to run tests and interviews as early as possible in the product development process. As time went by, more and more teams and stakeholders got convinced, that user research is a very sensible thing to do while creating and developing products.
As the amount of research we were doing increased, the number of insights and insight related documents increased as well. They were spread all over Sharepoint, which made it difficult for us to quickly look up, what we already know and share our knowledge easily.
We were in need of a single point of truth to look for all these valuable findings and to make them easily accessible. 🔎
Also we were looking for a place to bundle user feedback not only from qual an quant research measures, but from multiple sources like App store feedback, feedback from our support department, feedback that derived from our onsite feedback widget and the NPS (Net Promoter Score) that immowelt asks for on a regular basis. 🎯
What other goals did we persue?
- Making informed recommendations and decisions based on evidence
- Quantification of findings (base decisions and recommendations on occurring clusters of frequently identical or similar findings)
- Sustainable knowledge building (The development/change of products, or research objects in general, should become traceable over time)
- Transparency, accessibility and searchability for stakeholders and the team
- Improvement of visibility, usage and impact of research conducted
How did we do it?
After an extensive research phase on repositories of other companies (during which we also learned that it is not self-evident to have a research repository), we decided to use Airtable as our tool.
As Airtable describes it themselves it combines the power of a database with the familiarity of a spreadsheet. It also provides endless possibilities to automate processes and to visualize insights just to name a few (at least with the pro plan).
After we did our Research, we invested quite a bit of time into workshops, defining and designing the tables and bases we needed in order to represent our organizational structure and research related requirements the best possible way. This all happened through true team power!


Parts of our Miro Workshop Board
When our base was in place (thanks to a very engaged colleague) we started working with it. (And please note, that I only touched the surface of what had to be done for that to happen.)
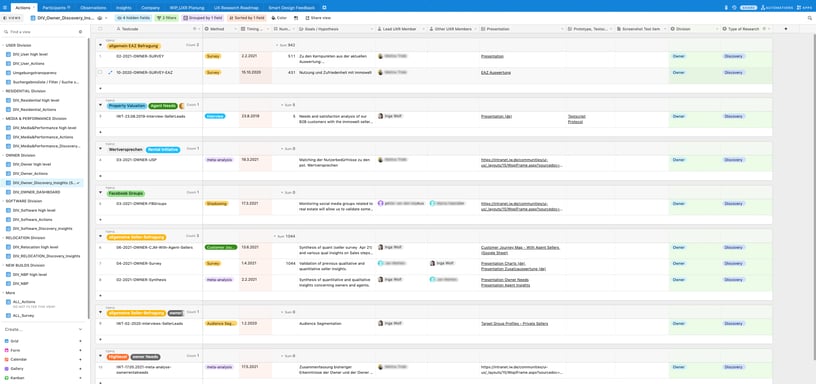
Since then, we have been analyzing our research actions, especially user tests and interviews, directly in Airtable, and capture observations, insights and recommendations, directly in the corresponding tables.
That way we also moved towards an increased standardisation and professionalisation of our work.
In addition to this, we reached a huge milestone by merging different user feedback sources into Airtbale. This was achieved, in short, through (Zapier) APIs, partly manual uploads and Airtable automation processes.
It allows us to identify and see the biggest problems and benefits for our users and (in theory) prioritize our roadmap accordingly.
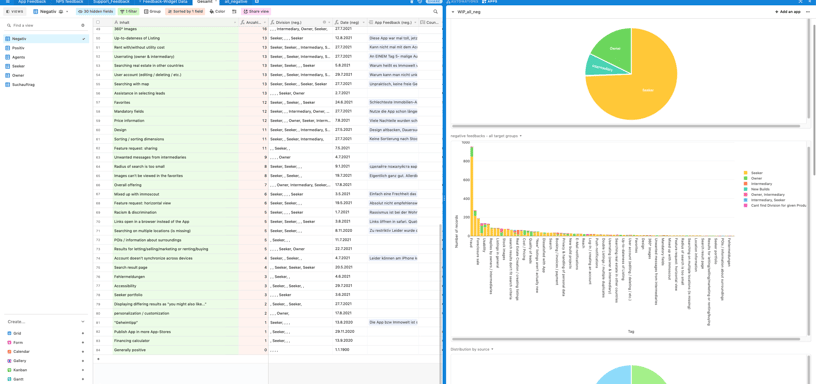

User Voice base in Airtable with visualization of top painpoints
Learnings and Outlook
With such a complex topic as a research repository, there is always room for improvement.
The approach to democratize our data was perceived very well within the company, but we found, for example, that it was difficult for our stakeholders to find the insights that were most relevant to them and not drown in the flood of detailed user test observations and insights.
Therefore, we have subsequently introduced the Type of Research column with the characteristics Tactical and Discovery. Discovery identifies our fundamental research findings, for which we have created special views (that can be created with the help of filters, sorting and grouping of data) per area of responsibility, so that the most important research actions with the corresponding insights can be recognized at a glance.
Taxonomy and Tagging is also something we continuously work on. It's important to speak the same language in order to make insights as easily searchable as possible. And it is quite a challenge too.
Also things that sound simple at first - such as the formulation of insights - continue to keep us busy. We noticed that everyone in the team formulated their insights differently, which is why we collected criteria for good insights so that we could all adhere to them in the future.
The list goes on and on, but all in all with setting up a Research Repository we have made a big leap forward towards increased UX maturity and we won't stop to continuously improve the repository step by step.